近日,集成电路顶会之一的IEEE定制集成电路大会(CICC)在美国德州圣安东尼奥举行。在本届CICC上,北京大学集成电路学院/集成电路高精尖创新中心有3篇高水平论文入选,向国际集成电路设计领域的同行展示了北京大学最新的研究成果。这三篇论文内容涉及模拟存算一体AI芯片、高能效电容传感器读出芯片、高能效混合架构脉冲神经网络芯片这三个学术前沿领域。论文的详情如下:
1. 模拟存算一体AI芯片
不断发展的AI算法对边缘端硬件的算力与能效提出了挑战。传统计算架构执行AI算法的瓶颈在于数据搬运功耗,即“存储墙”问题。为了解决这一问题,将计算嵌入到存储单元中并在模拟域完成乘累加运算的模拟存算一体AI芯片被提出。电流型计算因其高面积效率和高并行等特点,受到研究人员的青睐。然而目前的电流域模拟存算一体芯片受到晶体管非理想性的限制,无法在小电流下实现精确计算,因而存在着计算精度、能效瓶颈与鲁棒性多重挑战,其应用场景严重受限。
集成电路学院王源教授-唐希源研究员团队从电流型模拟存算一体电路的误差产生机制入手,首次提出了电流编程技术。该技术利用编程电流产生自校准的权重电压,实现多值模拟权重的高精度编程。同时,课题组提出了电压-电流两步编程模数,利用编程电压进行快速初步写入并用编程电流完成精确写入,大幅提高了多比特权重编程速度。此外,课题组提出了自偏置共源共栅读出结构,在无需额外偏置电路的情况下大幅增加了存储单元读出精度,降低了计算电流的对位线电压的敏感度。这三项技术使得电流型多值模拟存算单元可以无需校准地工作在小于1uA的计算电流下,突破了电流型存算一体电路的精度与能效瓶颈,并大幅提升其鲁棒性。
基于上述创新设计,课题组研制了一款基于65 nm CMOS工艺的电流型eDRAM模拟存内一体芯片,并对芯片进行了性能测试与汇报。在4-b输入/4-b权重/5-b输出精度的情况下,16Kb容量的原型芯片实现了233-304 TOPS/W的计算能效与2.963 TOPS/mm2的单位面积算力,达到了电流型存算一体电路中的国际领先水平。该创新通过将模拟权重的编程与计算统一到了电流域,大幅提高了模拟存算一体电流的计算精度与鲁棒性,可应用于边缘端AI计算场景。
该工作以A Calibration-Free 15-level/Cell eDRAM Computing-in-Memory Macro with 3T1C Current-Programmed Dynamic-Cascoded MLC achieving 233-to-304-TOPS/W 4b MAC为题,发表于今年CICC,文章的第一作者是北京大学集成电路学院博士后宋嘉豪,文章的通讯作者是唐希源研究员和王源教授。
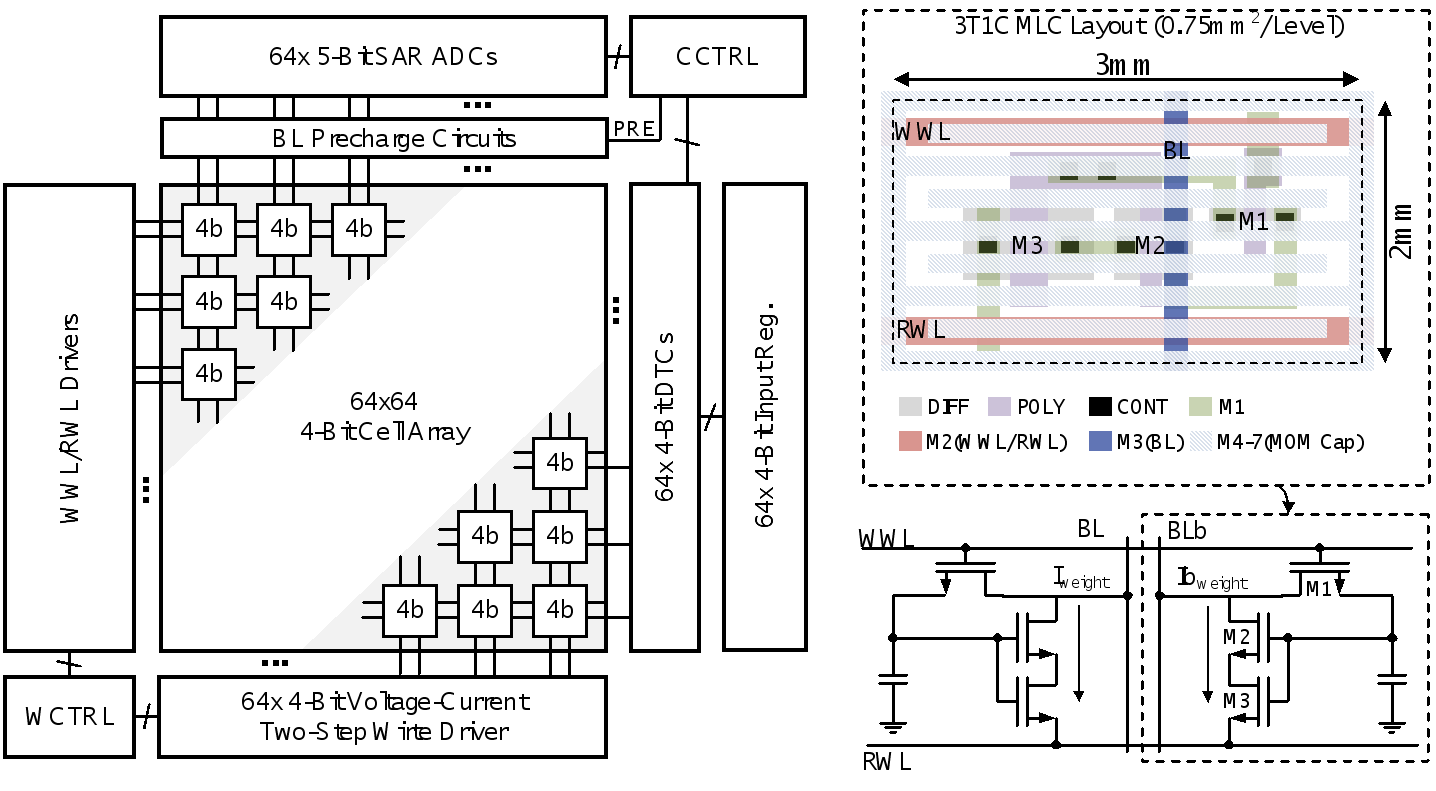
图1电流编程存算一体芯片计算单元与架构图

图2电流编程存算一体芯片显微照片
2. 高能效电容传感器读出芯片
电容传感器读出芯片被广泛应用于智慧医疗、运动监测等多种新兴物联网应用中。新兴应用对其精度、能效和转换延迟都提出了愈发严格的需求。
集成电路学院王源教授-唐希源研究员团队研制了一款时间域电容传感读出芯片,通过架构和电路层面协同设计与创新,该芯片实现了国际领先的读出能效和转换速度。在架构方面,该芯片采用了时间域信号处理,相比于传统的电压域设计,该方案更加高效、并能充分利用工艺演进带来的优势。该架构利用了单次采样多次量化的方案,大幅降低传感器采样开销,有效提升了系统能效并降低了转换延迟。在电路方面,该芯片利用双鉴频鉴相器对所有的相位信息进行量化,相比传统的鉴相器实现了2倍的转换精度提升。此外,该芯片设计了专门针对压控振荡器的快速启动技术,能够实现快速上下电,降低转换延迟的同时保证了首次转换精确(first conversion accurate),大幅拓展了其应用场景。
基于上述技术,课题组研制了一款基于28nm CMOS工艺的时间域增量型缩放式电容数字转换器芯片。该款芯片只需要单个传感器测量硬件,实现了1次采样10次量化的电容-数字的转换。该电路实现了0-5pF电容值测量范围,信噪比达到了77.7dB。在所有高精度(12-ENOB以上)电容数字转换器中实现了最低的测量延迟(4.1us)和最高的能效水平(9.7fJ/conv.-step)。该芯片的高精度、高能效、低延迟等特点,使其能够广泛应用于各类物联网传感器前端。
该工作以A 9.7fJ/Conv.-Step Capacitive Sensor Readout Circuit with Incremental Zoomed Time Domain Quantization为题,发表于今年CICC,文章的第一作者是北京大学集成电路学院博士生申子龙,文章的通讯作者是唐希源研究员和王源教授。
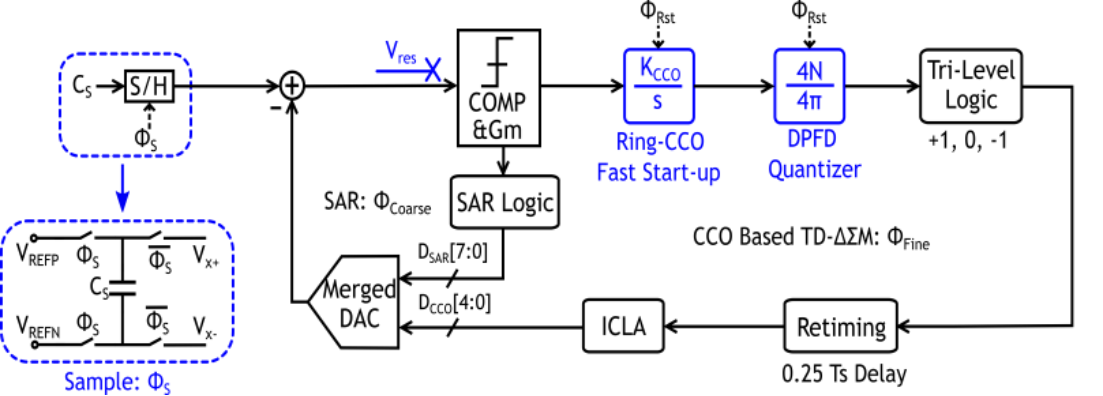
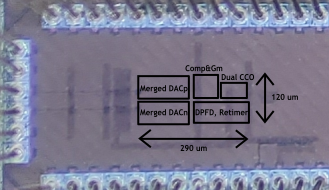
图3时间域增量型缩放式电容读出芯片架构图及显微照片
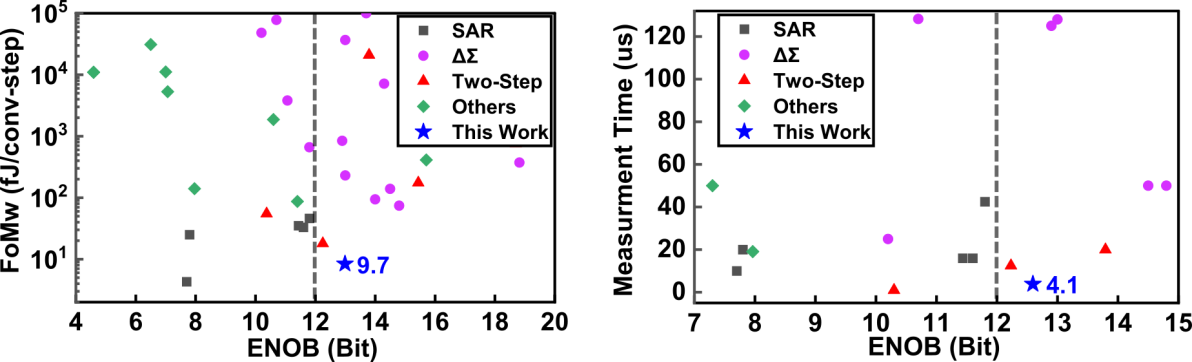
图4芯片性能对比图
3.高能效混合架构脉冲神经网络芯片
脉冲神经网络利用人脑中的脉冲处理机制,在低功耗,低延迟,高能效等各方面展现了巨大潜力,而人工神经网络可以通过基于梯度的反向传播(BP)训练达到高精度。如何高效结合两者优势成为当今研究技术难题。
集成电路学院黄如教授-叶乐教授团队研制了一款高能效混合架构脉冲神经网络芯片。通过在算法、架构和电路层面进行创新,该芯片可以同时实现了同类工作中最好的能效和高精度。在算法层面上,该芯片结合了反向传播算法和时空反传播算法(STBP)来训练网络,利用SNN来提取时间维度信息、提高了识别精度并减小了ANN网络规模。在架构层面上,该芯片具备高细粒度的可配置性,可以同时支持SNN神经元,ANN神经元以及SNN到ANN的转化过程,并根据脉冲稀疏性动态调整权重存储和工作负载。在电路层面上,课题组提出了功耗自适应输入稀疏性的存内计算阵列电路,其计算能力与输入和权重的稀疏性成正比,适用于具有ReLU激活的ANN和SNN中的稀疏操作。
基于上述技术,课题组研制了一款基于22nm纳米工艺的高能效混合架构脉冲神经网络芯片,并对该芯片的能耗、数据稀疏性和算法精度进行了测试。在心电异常检测和语音活跃度检测两个典型任务中,算法实现了98%和95%的识别率。测试结果表明,该芯片实现了同类工作中最好的动态能效0.43pJ/SOP,充分体现了S/ANN混合架构的高能效特点。这项工作是第一个具有稀疏感知内存计算和细粒度可配置性的混合SNN/ANN神经形态芯片。
该工作以A 22nm 0.43pJ/SOP Sparsity-Aware In-Memory Neuromorphic Computing System with Hybrid Spikingand Artificial Neural Network and Configurable Topology为题,发表于今年CICC,文章的第一作者是北京大学集成电路学院博士生刘影,文章的通讯作者是马宇飞研究员和叶乐教授。
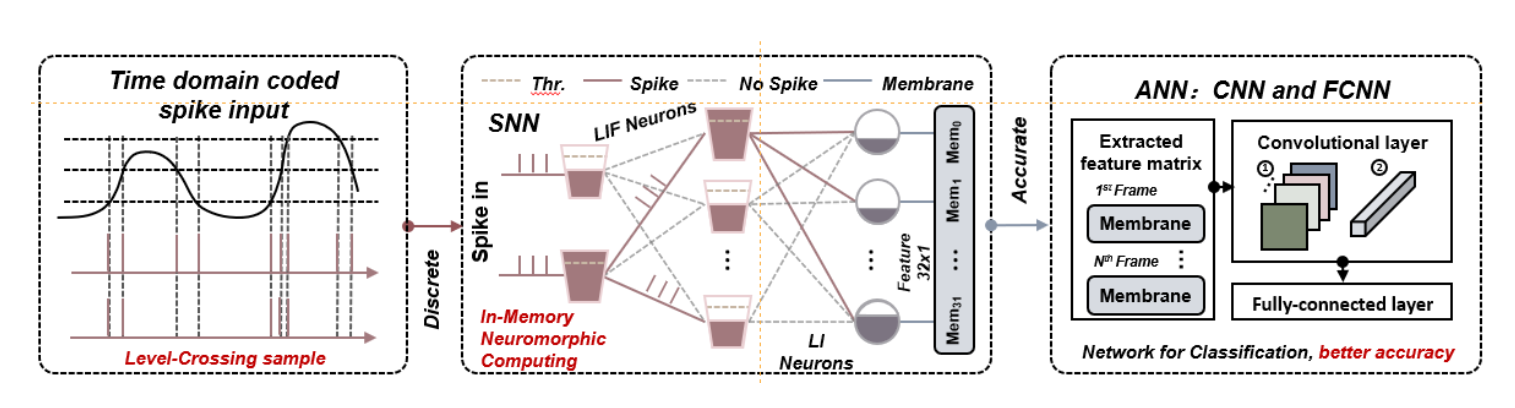
图5混合神经网络信息流图
 图6混合架构芯片显微照片
图6混合架构芯片显微照片
关于CICC
在集成电路芯片设计领域,IEEE固态电路协会(Solid-State Circuits Society)主办的定制集成电路会议(CICC)是IC设计领域顶级会议之一,以论文录用率低、作品创新性和实用性强著称,每年吸引全球范围内大量学术界、工业界研发人员的关注和参与。会议内容涉及模拟电路设计、生物医学、传感器、显示器和MEMS,数字和混合信号SoC/ASIC/SIP,嵌入式存储器件等方面,重点讨论如何解决集成电路设计问题的方法,以提高芯片各项性能指标。
